
Deepfake creation
Images contain information, and faces more so. In particular, facial information can be divided into two groups:
- Identity information: the specific facial characteristics that are particular to an individual: shape and placement of different parts of the face, including eyes, eyebrows, nose, mouth, overall shape, and so on.
- Expression information: the movement or deformation of parts of the face that constitute an expression: speaking, frowning, laughing, showing of emotions like joy, sadness, anger, surprise, etc.
Deepfakes mix the identity information of one individual with the expressions of another to create an artificially generated face. Additional, non-facial information is also included in the image: the bodies of persons, objects, environment, and background. This information may be derived from the source material of the identity or the expression, depending on the application and the desired outcome.
There are two main approaches to deepfake creation: Generative Adversarial Networks and Deep Autoencoders.
Generative Adversarial Networks (GANs)
GANs comprise two neural networks, trained in competition with each other (adversarial training): the Generator and the Discriminator.
The Generator is tasked with creating the desired deepfake image, given the necessary inputs (images from which to extract identity and expression). The Discriminator is tasked with figuring out if images are real or fake. When the Discriminator correctly identifies the Generator’s output as fake, it is rewarded. But when it is fooled, the Generator get rewarded instead.
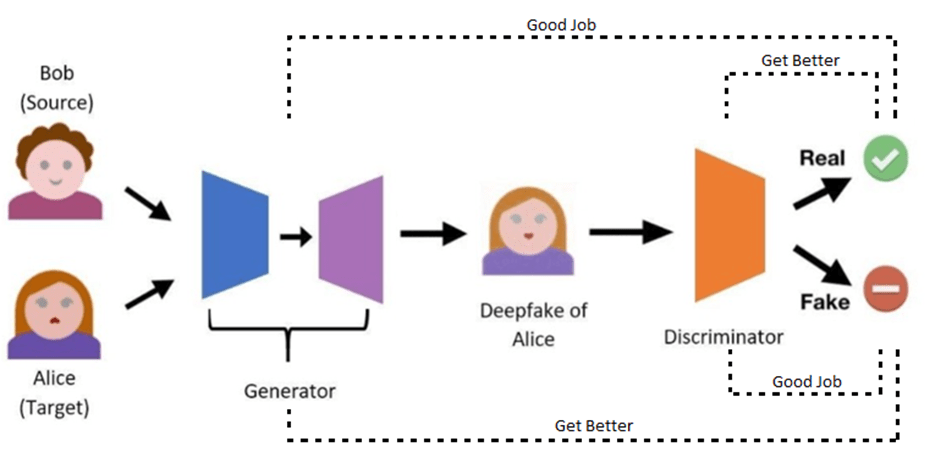
Figure 3: Typical deepfake GAN architecture. Image adapted from [1]
Via this simultaneous adversarial training, the Discriminator is pushed to become better at detecting fakes, and the Generator needs to become even better, to fool it. After training is complete, the Generator can produce realistic deepfake images.
Deep Autoencoders
An autoencoder is a neural network that is trained to compress an image into what is called a latent representation, and then de-compress this representation to acquire the original image. The latent representation contains compressed high-level information about the contents of the image, such as shapes, placements, relations, and meanings.
Normally, autoencoders are trained on vast collections of images, so that they can learn to process images of any content. However they can also be trained on very specific image collections, in which case they will specialize only in such content.
In order to create a deepfake of a specific individual (let’s name them person A), one can train an autoencoder twice: once on a generic large dataset containing many different faces; and once using only images of that specific person.
To create the deepfake, we take an image of another person (person B), and encode it using the generic autoencoder. For the decoding part, however, we use the autoencoder trained only in person A. That autoencoder has learned to interpret the latent representation only as person A. In effect, then, the expression of person B will be cast onto the identity of person A.
Imagine if someone describes to you an image of a person: “a man is smiling, looking at the camera; his teeth are slightly parted; he has short brown hair, parted a bit on the right side”. But the only person you have ever seen in your life is Tom Cruise, so you can only imagine Tom Cruise with this description.

Figure 4: Deepfake casting a man’s expression on the identity of Tom Cruise [2]
Deepfake detection
How to detect deepfakes, though? To a large extend, this depends on their sophistication. Older on less sophisticated deepfakes have some obvious mistakes, which a careful observer may notice: Abnormalities in texture and lighting; weird teeth, nose or hair; unnatural movement of eyelids or brows; indecipherable text; surreal background; muted emotional expressions; and other incongruous details.
Better deepfakes may have none of those errors; just check the image of Tom Cruise above. It will be very difficult – or downright impossible – for a human observer to detect these as fakes.
The key word here is “human”. The newest approaches to deepfake detection employ deep learning neural networks to differentiate between real and deepfaked images. As the saying goes, fighting fire with fire.
Although there are many methods being researched to that purpose, they can be generally divided into two categories: one-shot detection and feature-based detection.
One-shot methods
Similar to the human observer (but equipped with infinite patience and meticulous attention to detail), one-shot methods learn to detected the abnormalities commonly produced by deepfake creation methods. These methods are trained on huge numbers of images: some are real, and some are fake, and during training, the AI knows which is which; thus it learns to tell them apart.
At the same time, this dependence on a large collection of images for training can be a problem. While there is an abundance of real images, there is not (yet) a huge collection of fakes that can be used for such training. Another drawback is the methods such fakes are created. By necessity, the network will only learn to detect deepfakes created by the same methods that used for the training collection. Fakes created by newer or different methods might not be detected. And new methods are developed all the time.
Feature-based methods
Feature-based methods focus on learning the characteristics of a single person and are trained to detect fakes of that particular person. In effect, they don’t directly answer to the question “is this real or fake?” but instead transform it into an equivalent: “Is this Tom Cruise?”
These AIs are each trained on a specific individual (let’s call him Tom) and learn his characteristics very well indeed. They go beyond purely surface details and learn the structure, expression, and mannerisms of their assigned person. Their advantage lies in that they don’t need a huge collection of images to train; they only need a few videos of Tom, all of them real. In addition, they are largely independent of deepfake creation methods, as they do not train on fakes at all.
EITHOS’s research on deepfake detection will focus on such feature-based methods.
References
- Illumin Magazine: Deepfakes: Fooling Humans with Artificial Intelligence, https://illumin.usc.edu/deepfakes-fooling-humans-with-artificial-intelligence/
- VFXChris Ume: DeepTomCruise Tiktok Breakdown, https://www.youtube.com/watch?v=wq-kmFCrF5Q